I am very happy to share that I’ve had five papers accepted at the ACM International Conference on Multimodal Interaction. These papers cover a variety of recent research projects, from ultrasound haptic perception to new haptic authentication techniques.
HapticLock
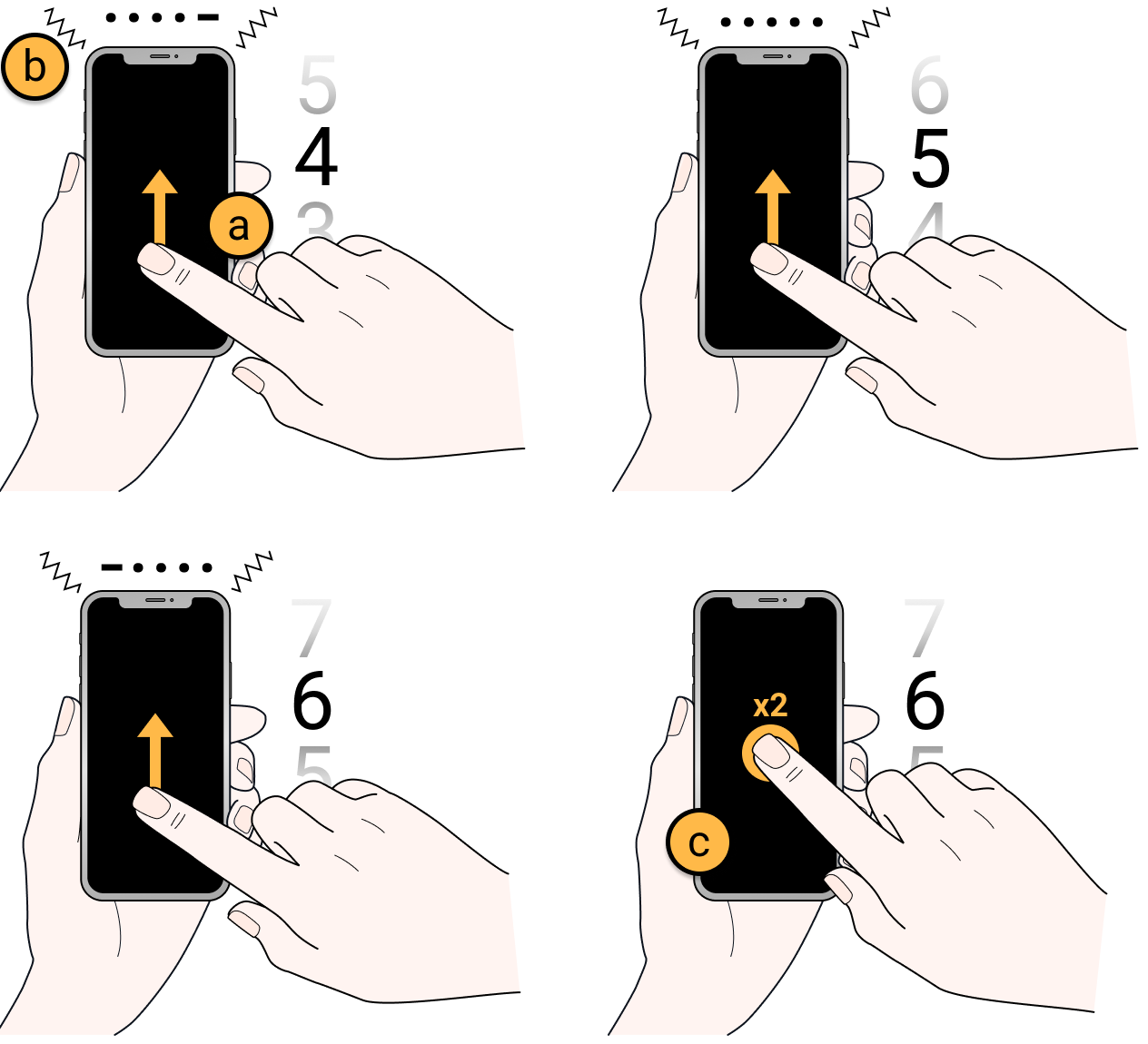
This paper describes HapticLock, a novel eyes-free authentication method for smartphones. It uses touchscreen swipe gestures to select PIN digits, with Morse Code vibrations given as feedback. This allows eyes-free PIN entry and mitigate against observational and thermal attacks. This paper was the outcome from an excellent undergraduate student research project.
HapticLock: Eyes-Free Authentication for Mobile Devices
G. Dhandapani, J. Ferguson, and E. Freeman.
In Proceedings of 23rd ACM International Conference on Multimodal Interaction – ICMI ’21, 195-202. 2021.
@inproceedings{ICMI2021HapticLock,
author = {Dhandapani, Gloria and Ferguson, Jamie and Freeman, Euan},
booktitle = {{Proceedings of 23rd ACM International Conference on Multimodal Interaction - ICMI '21}},
title = {{HapticLock: Eyes-Free Authentication for Mobile Devices}},
year = {2021},
publisher = {ACM},
pages = {195--202},
doi = {10.1145/3462244.3481001},
url = {http://euanfreeman.co.uk/hapticlock-eyes-free-authentication-for-mobile-devices/},
pdf = {http://research.euanfreeman.co.uk/papers/ICMI_2021_HapticLock.pdf},
}Ultrasound Haptic Perception
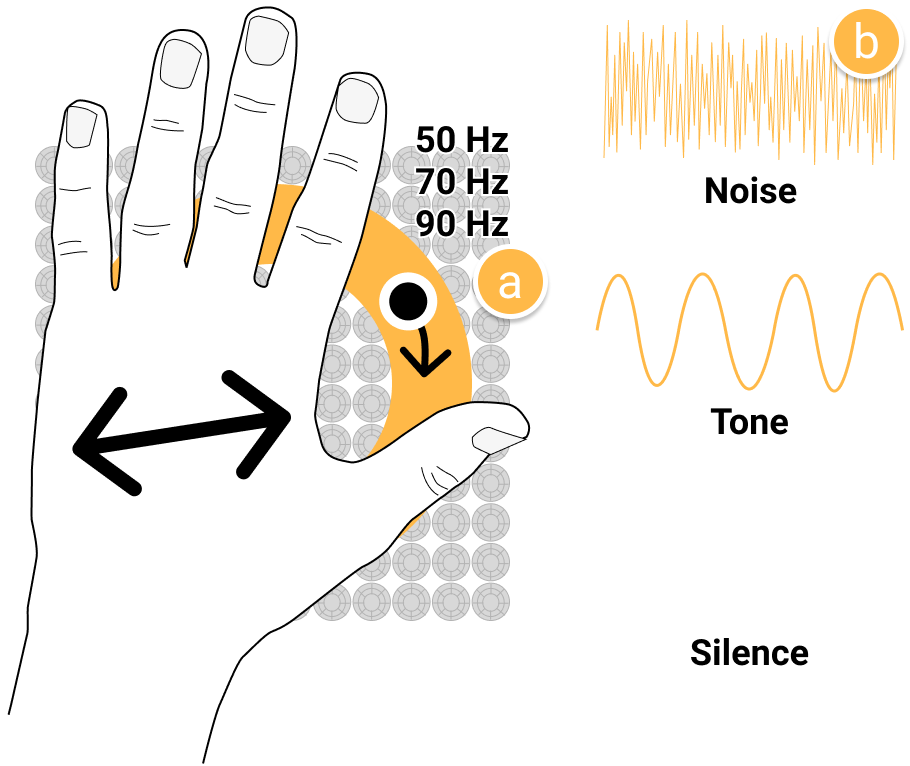
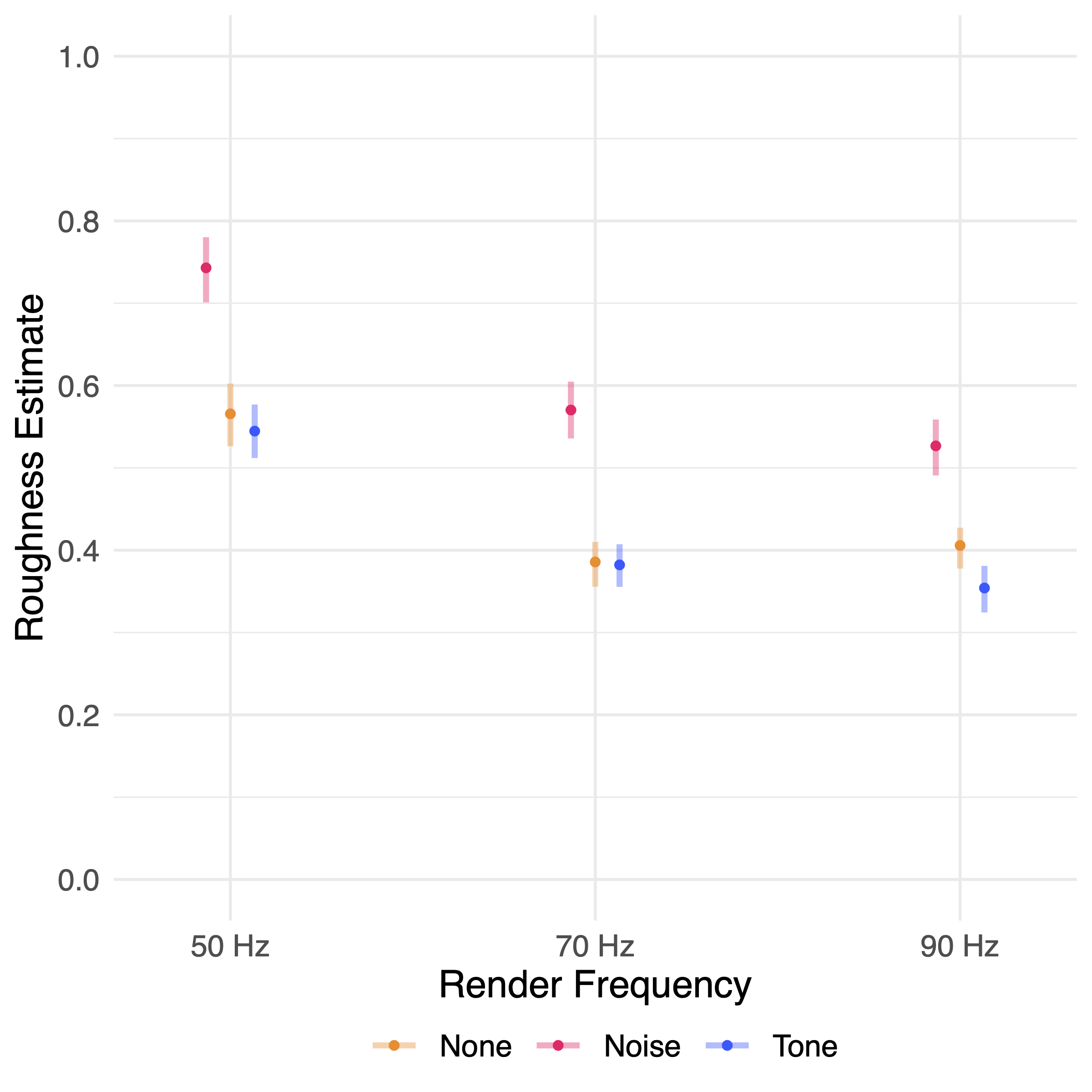
Two of my papers describe experiments about ultrasound haptic perception. One is about the perception of motion arising from spatially modulated circular patterns. The other is about ultrasound haptics with parametric audio effects. The latter paper shows that white noise sound effects from an ultrasound haptics device can increase the perceived roughness of a normal circular haptic pattern. It also shows that lower rendering frequencies may be perceived as rougher than higher frequencies.
Enhancing Ultrasound Haptics with Parametric Audio Effects
E. Freeman.
In Proceedings of 23rd ACM International Conference on Multimodal Interaction – ICMI ’21, 692-696. 2021.
@inproceedings{ICMI2021AudioHaptic,
author = {Freeman, Euan},
booktitle = {{Proceedings of 23rd ACM International Conference on Multimodal Interaction - ICMI '21}},
title = {{Enhancing Ultrasound Haptics with Parametric Audio Effects}},
year = {2021},
publisher = {ACM},
pages = {692--696},
doi = {10.1145/3462244.3479951},
url = {http://euanfreeman.co.uk/enhancing-ultrasound-haptics-with-parametric-audio-effects/},
pdf = {http://research.euanfreeman.co.uk/papers/ICMI_2021_AudioHaptic.pdf},
data = {https://zenodo.org/record/5144878},
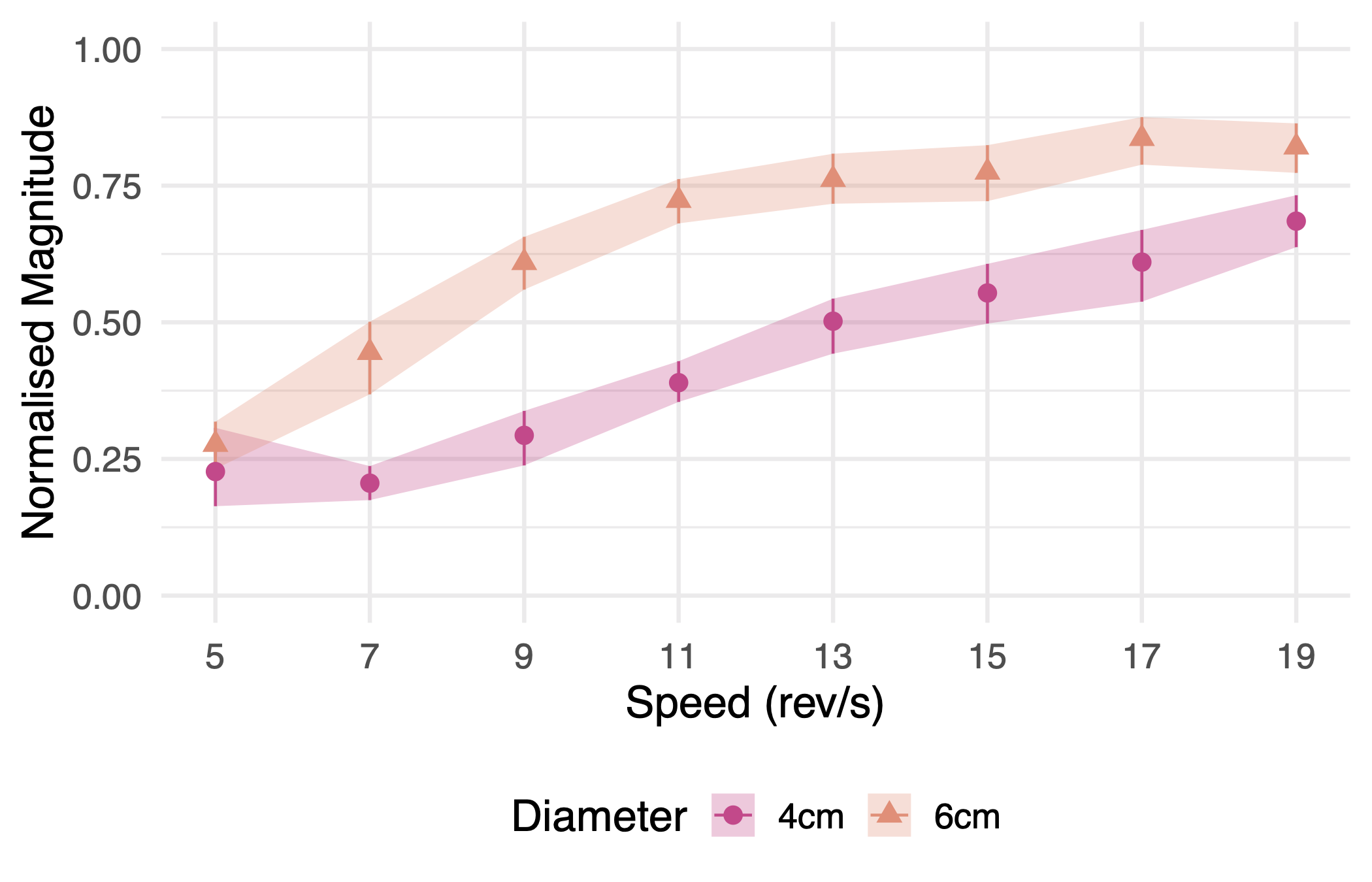
} Perception of Ultrasound Haptic Focal Point Motion
E. Freeman and G. Wilson.
In Proceedings of 23rd ACM International Conference on Multimodal Interaction – ICMI ’21, 697-701. 2021.
@inproceedings{ICMI2021Motion,
author = {Freeman, Euan and Wilson, Graham},
booktitle = {{Proceedings of 23rd ACM International Conference on Multimodal Interaction - ICMI '21}},
title = {{Perception of Ultrasound Haptic Focal Point Motion}},
year = {2021},
publisher = {ACM},
pages = {697--701},
doi = {10.1145/3462244.3479950},
url = {http://euanfreeman.co.uk/perception-of-ultrasound-haptic-focal-point-motion/},
pdf = {http://research.euanfreeman.co.uk/papers/ICMI_2021_Motion.pdf},
data = {https://zenodo.org/record/5142587},
}Calming Haptics for Social Situations
This paper, led by a PhD student at University of Glasgow, describes a qualitative investigation into user preferences for calming haptic stimuli. This is part of a broader project looking at how haptics can potentially be used to present calming and reassuring stimuli in anxiety inducing social situations.
User Preferences for Calming Affective Haptic Stimuli in Social Settings
S. A. Macdonald, E. Freeman, S. Brewster, and F. Pollick.
In Proceedings of 23rd ACM International Conference on Multimodal Interaction – ICMI ’21, 387-396. 2021.
@inproceedings{ICMI2021Affective,
author = {Macdonald, Shaun A. and Freeman, Euan and Brewster, Stephen and Pollick, Frank},
booktitle = {{Proceedings of 23rd ACM International Conference on Multimodal Interaction - ICMI '21}},
title = {{User Preferences for Calming Affective Haptic Stimuli in Social Settings}},
year = {2021},
publisher = {ACM},
pages = {387--396},
doi = {10.1145/3462244.3479903},
pdf = {http://research.euanfreeman.co.uk/papers/ICMI_2021_Calming.pdf},
}Polarity of Audio/Vibrotactile Encodings
This paper describes a study investigating response to audio and vibrotactile patterns under varying levels of cognitive load. We looked at opposing encoding polarity, to see if this affected reaction time and interpretation accuracy, challenging the idea that the most ‘intuitive’ polarity will yield the fastest and most accurate responses.
Investigating the Effect of Polarity in Auditory and Vibrotactile Displays Under Cognitive Load
J. Ferguson, E. Freeman, and S. Brewster.
In Proceedings of 23rd ACM International Conference on Multimodal Interaction – ICMI ’21, 379-386. 2021.
@inproceedings{ICMI2021Polarity,
author = {Ferguson, Jamie and Freeman, Euan and Brewster, Stephen},
booktitle = {{Proceedings of 23rd ACM International Conference on Multimodal Interaction - ICMI '21}},
title = {{Investigating the Effect of Polarity in Auditory and Vibrotactile Displays Under Cognitive Load}},
year = {2021},
publisher = {ACM},
pages = {379--386},
doi = {10.1145/3462244.3479911},
pdf = {http://research.euanfreeman.co.uk/papers/ICMI_2021_Polarity.pdf},
}